Database
Database Replication
Replication is a process that involves sharing information to ensure consistency between redundant resources such as multiple databases, to improve reliability, fault-tolerance, or accessibility.
Master-Slave Replication
The master serves reads and writes, replicating writes to one or more slaves, which serve only reads. Slaves can also replicate additional slaves in a tree-like fashion. If the master goes offline, the system can continue to operate in read-only mode until a slave is promoted to a master or a new master is provisioned.
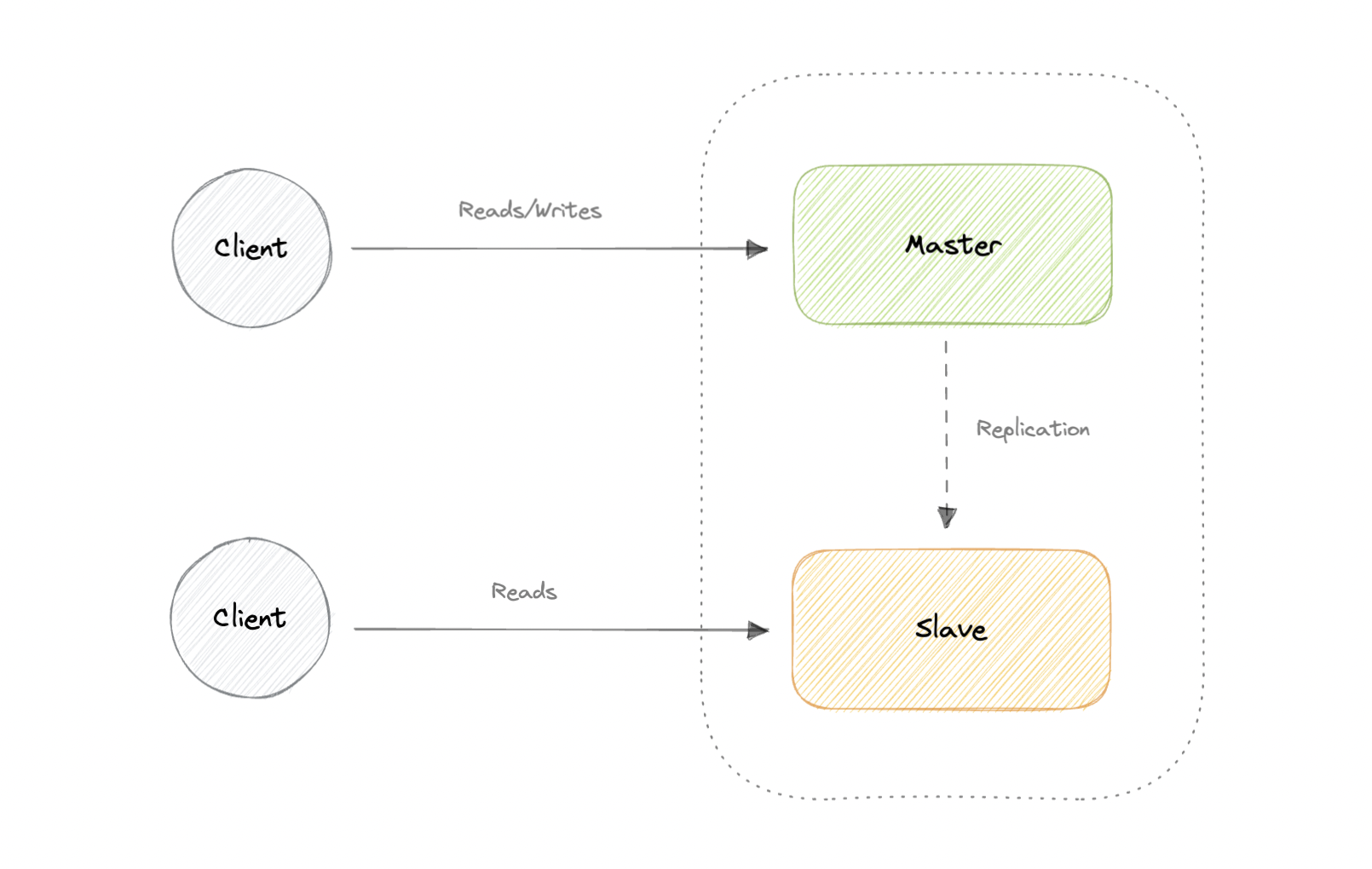
Advantages:
- Backups of the entire database of relatively no impact on the master.
- Applications can read from the slave(s) without impacting the master.
- Slaves can be taken offline and synced back to the master without any downtime.
Disadvantages:
- Replication adds more hardware and additional complexity.
- Downtime and possibly loss of data when a master fails.
- All writes also have to be made to the master in a master-slave architecture.
- The more read slaves, the more we have to replicate, which will increase replication lag.
Master-Master Replication
Both masters serve reads/writes and coordinate with each other. If either master goes down, the system can continue to operate with both reads and writes.
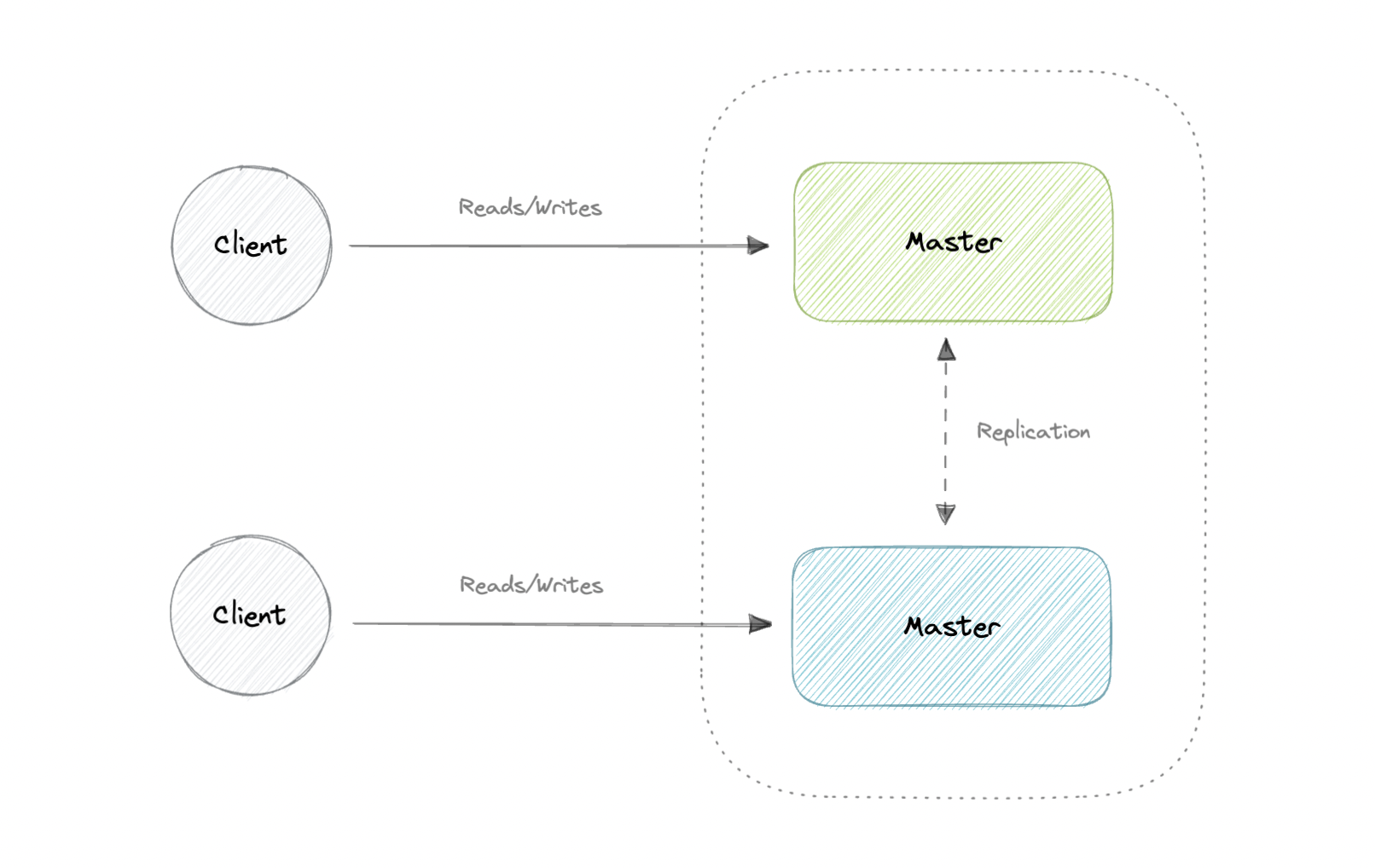
Advantages:
- Applications can read from both masters.
- Distributes write load across both master nodes.
- Simple, automatic, and quick failover.
Disadvantages:
- Not as simple as master-slave to configure and deploy.
- Either loosely consistent or have increased write latency due to synchronization.
- Conflict resolution comes into play as more write nodes are added and as latency increases.
Synchronous vs Asynchronous replication
The primary difference between synchronous and asynchronous replication is how the data is written to the replica. In synchronous replication, data is written to primary storage and the replica simultaneously. As such, the primary copy and the replica should always remain synchronized.
In contrast, asynchronous replication copies the data to the replica after the data is already written to the primary storage. Although the replication process may occur in near-real-time, it is more common for replication to occur on a scheduled basis and it is more cost-effective.
Indexes
Indexes are well known when it comes to databases, they are used to improve the speed of data retrieval operations on the data store. An index makes the trade-offs of increased storage overhead, and slower writes (since we not only have to write the data but also have to update the index) for the benefit of faster reads. Indexes are used to quickly locate data without having to examine every row in a database table. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access to ordered records.
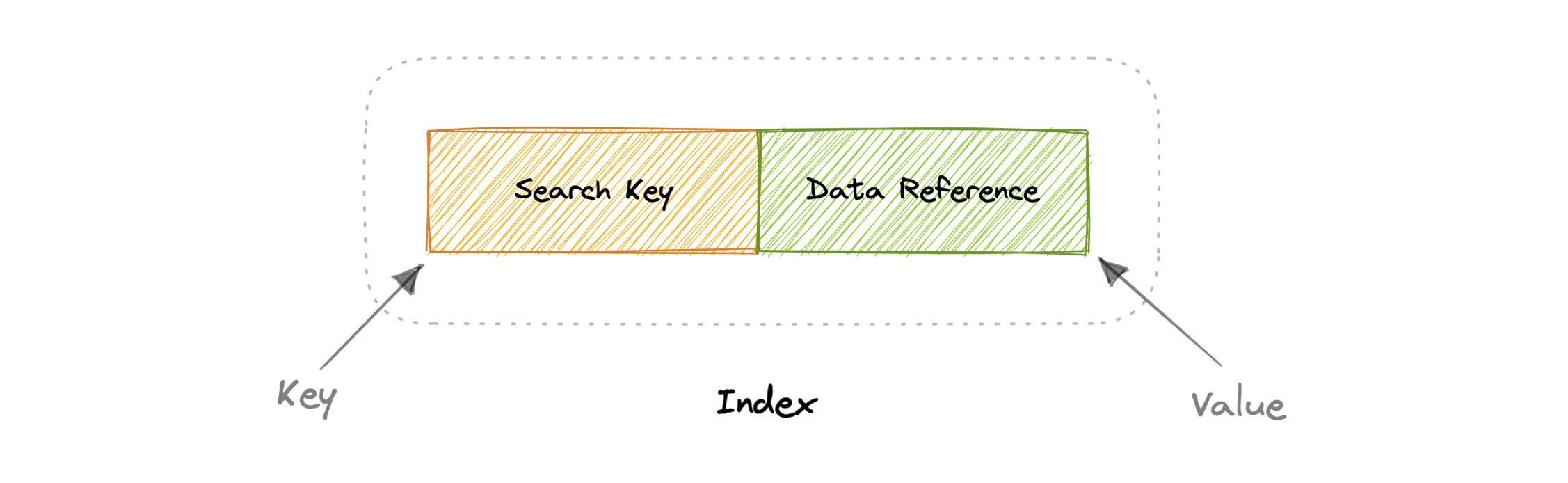
An index is a data structure that can be perceived as a table of contents that points us to the location where actual data lives. So when we create an index on a column of a table, we store that column and a pointer to the whole row in the index. Indexes are also used to create different views of the same data. For large data sets, this is an excellent way to specify different filters or sorting schemes without resorting to creating multiple additional copies of the data.
One quality that database indexes can have is that they can be dense or sparse. Each of these index qualities comes with its own trade-offs. Let's look at how each index type would work:
Dense Index
In a dense index, an index record is created for every row of the table. Records can be located directly as each record of the index holds the search key value and the pointer to the actual record.
Dense indexes require more maintenance than sparse indexes at write-time. Since every row must have an entry, the database must maintain the index on inserts, updates, and deletes. Having an entry for every row also means that dense indexes will require more memory. The benefit of a dense index is that values can be quickly found with just a binary search. Dense indexes also do not impose any ordering requirements on the data.
Sparse Index
In a sparse index, records are created only for some of the records.

Sparse indexes require less maintenance than dense indexes at write-time since they only contain a subset of the values. This lighter maintenance burden means that inserts, updates, and deletes will be faster. Having fewer entries also means that the index will use less memory. Finding data is slower since a scan across the page typically follows the binary search. Sparse indexes are also optional when working with ordered data.
ACID Model
ACID is an acronym that refers to the set of 4 key properties that define a transaction: Atomicity, Consistency, Isolation, and Durability. If a database operation has these ACID properties, it can be called an ACID transaction, and data storage systems that apply these operations are called transactional systems. ACID transactions guarantee that each read, write, or modification of a table has the following properties:
In order to maintain consistency before and after a transaction relational databases follow ACID properties. Let us understand these terms:
Atomic
- Each statement in a transaction (to read, write, update or delete data) is treated as a single unit. Either the entire statement is executed, or none of it is executed. This property prevents data loss and corruption from occurring if, for example, if your streaming data source fails mid-stream.
Consistent
- Ensures that transactions only make changes to tables in predefined, predictable ways. Transactional consistency ensures that corruption or errors in your data do not create unintended consequences for the integrity of your table.
Isolated
- When multiple users are reading and writing from the same table all at once, isolation of their transactions ensures that the concurrent transactions don't interfere with or affect one another. Contentious access to data is moderated by the database so that transactions appear to run sequentially.
Durable
- Once the transaction has been completed and the writes and updates have been written to the disk, it will remain in the system even if a system failure occurs.
BASE Model
With the increasing amount of data and high availability requirements, the approach to database design has also changed dramatically. To increase the ability to scale and at the same time be highly available, we move the logic from the database to separate servers. In this way, the database becomes more independent and focused on the actual process of storing data.
In the NoSQL database world, ACID transactions are less common as some databases have loosened the requirements for immediate consistency, data freshness, and accuracy in order to gain other benefits, like scale and resilience.
BASE properties are much looser than ACID guarantees, but there isn't a direct one-for-one mapping between the two consistency models.
Basic Availability
- The database appears to work most of the time.
Soft-state
- Stores don't have to be write-consistent, nor do different replicas have to be mutually consistent all the time.
Eventual consistency
- The data might not be consistent immediately but eventually, it becomes consistent. Reads in the system are still possible even though they may not give the correct response due to inconsistency.
CAP Theorem
CAP theorem states that a distributed system can deliver only two of the three desired characteristics Consistency, Availability, and Partition tolerance (CAP).
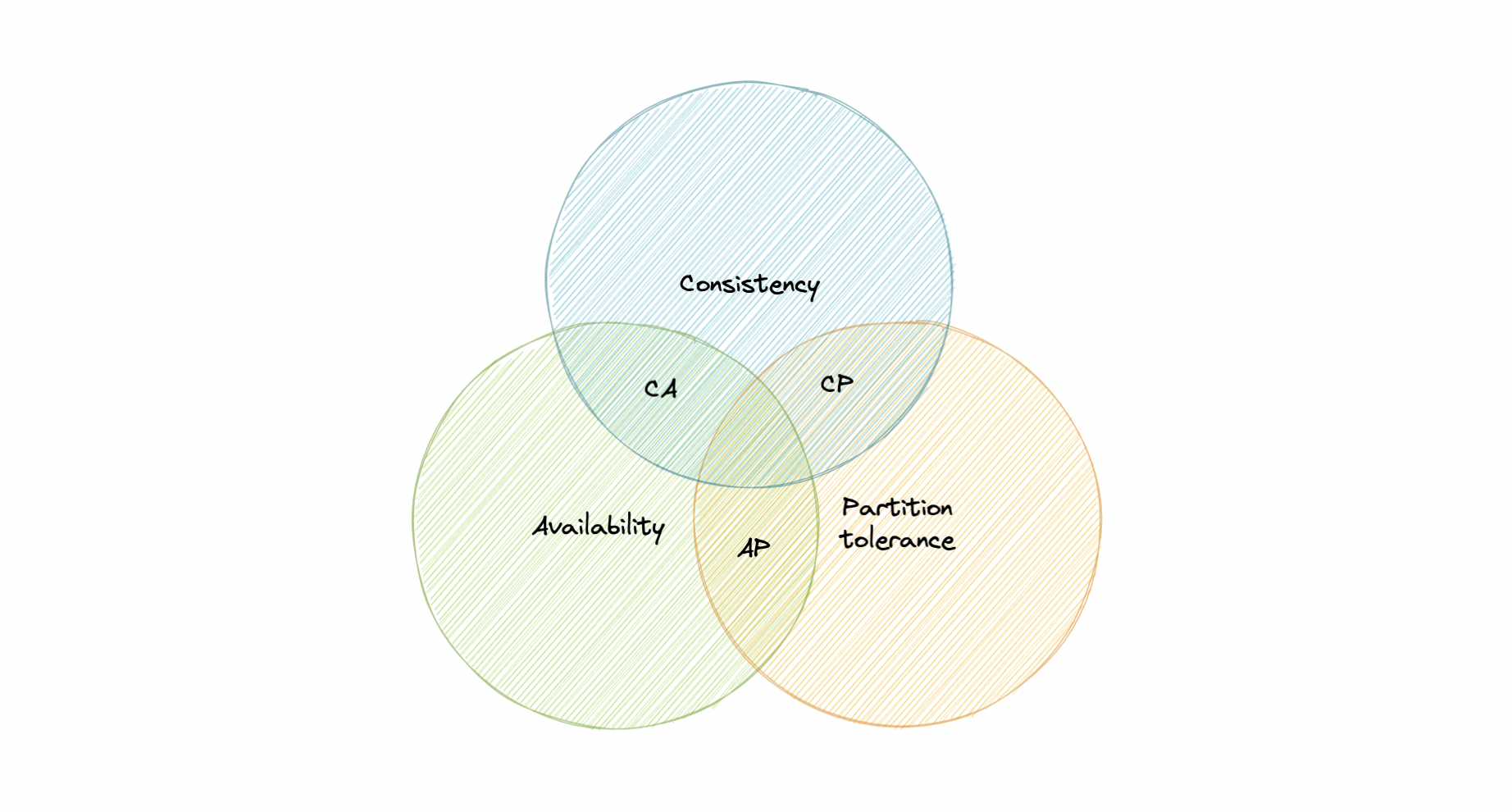
Consistency
- Consistency means that all clients see the same data at the same time, no matter which node they connect to. For this to happen, whenever data is written to one node, it must be instantly forwarded or replicated across all the nodes in the system before the write is deemed "successful".
Availability
- Availability means that any client making a request for data gets a response, even if one or more nodes are down.
Partition tolerance
- Partition tolerance means the system continues to work despite message loss or partial failure. A system that is partition-tolerant can sustain any amount of network failure that doesn't result in a failure of the entire network. Data is sufficiently replicated across combinations of nodes and networks to keep the system up through intermittent outages.
In any networked shared-data systems partition tolerance is a must. Consequently, system designers must choose between consistency and availability. Simplistically speaking, a network partition forces designers to either choose perfect consistency or perfect availability. picking consistency means not being able to answer a client's query as the system cannot guarantee to return the most recent writes, which sacrifices availability.
Network partition forces nonfailing nodes to reject clients' requests as these nodes cannot guarantee consistent data. At the opposite end of the spectrum, being available means being able to respond to a client's request but the system cannot guarantee consistency, i.e., the most recent value written. Available systems provide the best possible answer under the given circumstance.
Transactions
A transaction is a series of database operations that are considered to be a "single unit of work". The operations in a transaction either all succeed, or they all fail. In this way, the notion of a transaction supports data integrity when part of a system fails. Not all databases choose to support ACID transactions, usually because they are prioritizing other optimizations that are hard or theoretically impossible to implement together.
Usually, relational databases support ACID transactions, and non-relational databases don't (there are exceptions).
Transaction States
![]()
Active
- In this state, the transaction is being executed. This is the initial state of every transaction.
Partially Committed
- When a transaction executes its final operation, it is said to be in a partially committed state.
Committed
- If a transaction executes all its operations successfully, it is said to be committed. All its effects are now permanently established on the database system.
Failed
- The transaction is said to be in a failed state if any of the checks made by the database recovery system fails. A failed transaction can no longer proceed further.
Aborted
- If any of the checks fail and the transaction has reached a failed state, then the recovery manager rolls back all its write operations on the database to bring the database back to its original state where it was prior to the execution of the transaction. Transactions in this state are aborted.
The database recovery module can select one of the two operations after a transaction aborts:
- Restart the transaction
- Kill the transaction
Terminated
- If there isn't any roll-back or the transaction comes from the committed state, then the system is consistent and ready for a new transaction and the old transaction is terminated.
Data Partitioning
Data partitioning is a technique to break up a database into many smaller parts. It is the process of splitting up a database or a table across multiple machines to improve the manageability, performance, and availability of a database.
There are many different ways one could use to decide how to break up an application database into multiple smaller DBs. Below are three of the most popular methods used by various large-scale applications:
- Horizontal Partitioning (or Sharding)
In this strategy, we split the table data horizontally based on the range of values defined by the partition key. It is also referred to as database sharding.
- Vertical Partitioning
In vertical partitioning, we partition the data vertically based on columns. We divide tables into relatively smaller tables with few elements, and each part is present in a separate partition.
What is sharding?
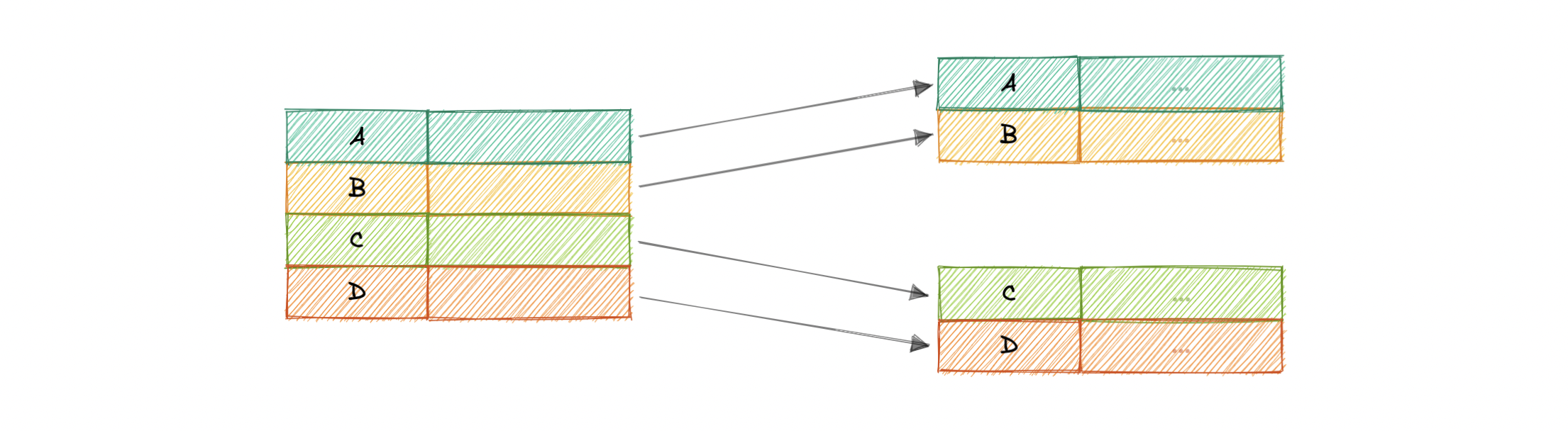
Sharding is a database architecture pattern related to horizontal partitioning — the practice of separating one table’s rows into multiple different tables, known as partitions. Each partition has the same schema and columns, but also entirely different rows. Likewise, the data held in each is unique and independent of the data held in other partitions.
It can be helpful to think of horizontal partitioning in terms of how it relates to vertical partitioning. In a vertically-partitioned table, entire columns are separated out and put into new, distinct tables. The data held within one vertical partition is independent from the data in all the others, and each holds both distinct rows and columns. The following diagram illustrates how a table could be partitioned both horizontally and vertically:
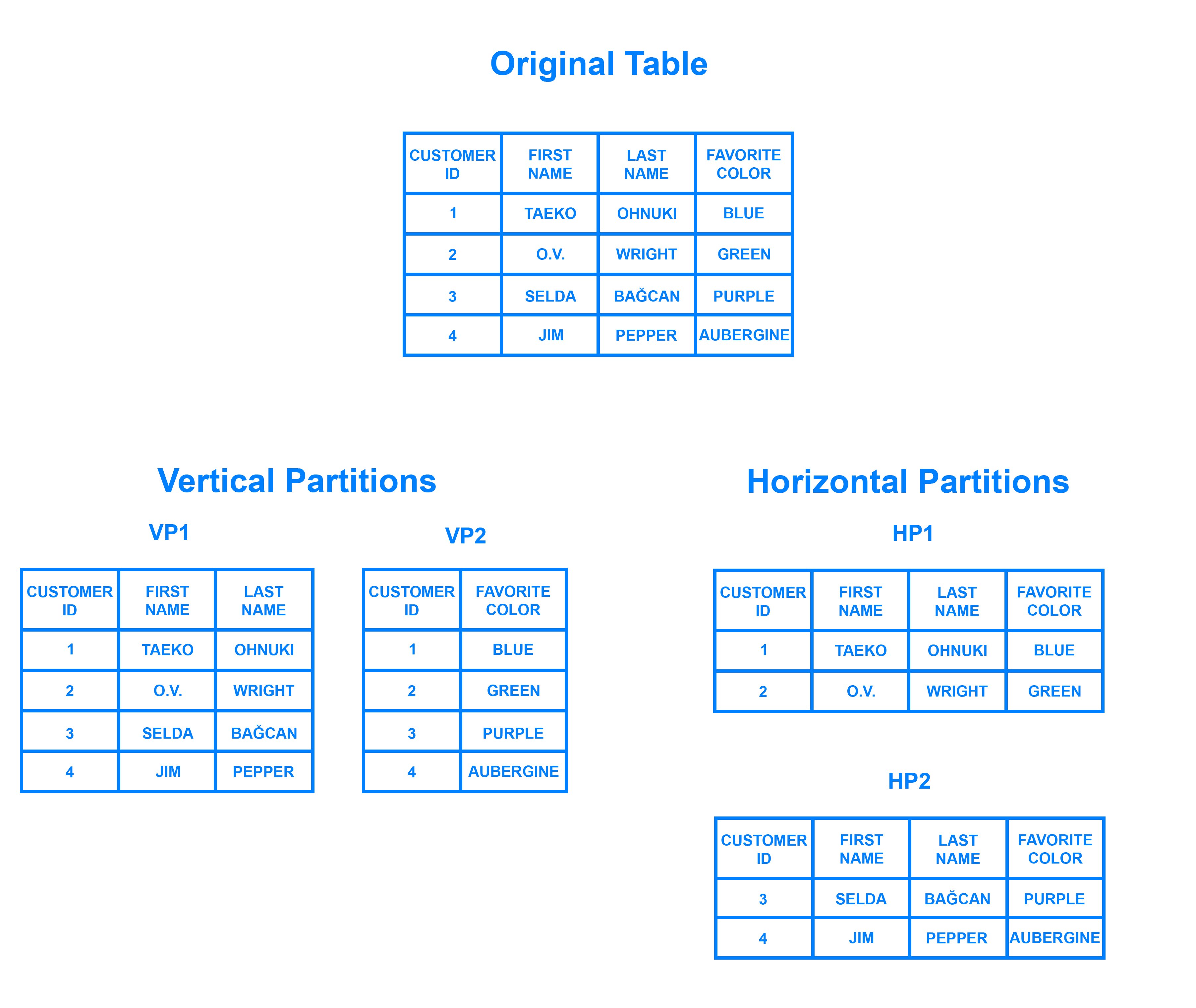
Sharding involves breaking up one’s data into two or more smaller chunks, called logical shards. The logical shards are then distributed across separate database nodes, referred to as physical shards, which can hold multiple logical shards. Despite this, the data held within all the shards collectively represent an entire logical dataset.
Database shards exemplify a shared-nothing architecture. This means that the shards are autonomous; they don’t share any of the same data or computing resources. In some cases, though, it may make sense to replicate certain tables into each shard to serve as reference tables. For example, let’s say there’s a database for an application that depends on fixed conversion rates for weight measurements. By replicating a table containing the necessary conversion rate data into each shard, it would help to ensure that all of the data required for queries is held in every shard.
Oftentimes, sharding is implemented at the application level, meaning that the application includes code that defines which shard to transmit reads and writes to. However, some database management systems have sharding capabilities built in, allowing you to implement sharding directly at the database level.
Partitioning criteria
There are a large number of criteria available for data partitioning. Some most commonly used criteria are:
Hash-Based
-
Key based sharding, also known as hash based sharding, involves using a value taken from newly written data — such as a customer’s ID number, a client application’s IP address, a ZIP code, etc. — and plugging it into a hash function to determine which shard the data should go to. A hash function is a function that takes as input a piece of data (for example, a customer email) and outputs a discrete value, known as a hash value. In the case of sharding, the hash value is a shard ID used to determine which shard the incoming data will be stored on. Altogether, the process looks like this:
-
To ensure that entries are placed in the correct shards and in a consistent manner, the values entered into the hash function should all come from the same column. This column is known as a shard key. In simple terms, shard keys are similar to primary keys in that both are columns which are used to establish a unique identifier for individual rows. Broadly speaking, a shard key should be static, meaning it shouldn’t contain values that might change over time. Otherwise, it would increase the amount of work that goes into update operations, and could slow down performance.
-
While key based sharding is a fairly common sharding architecture, it can make things tricky when trying to dynamically add or remove additional servers to a database. As you add servers, each one will need a corresponding hash value and many of your existing entries, if not all of them, will need to be remapped to their new, correct hash value and then migrated to the appropriate server. As you begin rebalancing the data, neither the new nor the old hashing functions will be valid. Consequently, your server won’t be able to write any new data during the migration and your application could be subject to downtime.

- The disadvantage of this method is that dynamically adding/removing database servers becomes expensive.
List-Based
- In list-based partitioning, each partition is defined and selected based on the list of values on a column rather than a set of contiguous ranges of values.
Range Based
-
Range based sharding involves sharding data based on ranges of a given value. To illustrate, let’s say you have a database that stores information about all the products within a retailer’s catalog. You could create a few different shards and divvy up each products’ information based on which price range they fall into, like this:

-
The main benefit of range based sharding is that it’s relatively simple to implement. Every shard holds a different set of data but they all have an identical schema as one another, as well as the original database. The application code reads which range the data falls into and writes it to the corresponding shard.
-
On the other hand, range based sharding doesn’t protect data from being unevenly distributed, leading to the aforementioned database hotspots. Looking at the example diagram, even if each shard holds an equal amount of data the odds are that specific products will receive more attention than others. Their respective shards will, in turn, receive a disproportionate number of reads.
Composite
- As the name suggests, composite partitioning partitions the data based on two or more partitioning techniques. Here we first partition the data using one technique, and then each partition is further subdivided into sub-partitions using the same or some other method.
Advantages
But why do we need sharding? Here are some advantages:
-
Availability: Provides logical independence to the partitioned database, ensuring the high availability of our application. Sharding can also help to make an application more reliable by mitigating the impact of outages. If your application or website relies on an unsharded database, an outage has the potential to make the entire application unavailable. With a sharded database, though, an outage is likely to affect only a single shard. Even though this might make some parts of the application or website unavailable to some users, the overall impact would still be less than if the entire database crashed
-
Scalability: Proves to increase scalability by distributing the data across multiple partitions.
-
Security: Helps improve the system's security by storing sensitive and non-sensitive data in different partitions. This could provide better manageability and security to sensitive data.
-
Query Performance: Improves the performance of the system. When you submit a query on a database that hasn’t been sharded, it may have to search every row in the table you’re querying before it can find the result set you’re looking for. For an application with a large, monolithic database, queries can become prohibitively slow. By sharding one table into multiple, though, queries have to go over fewer rows and their result sets are returned much more quickly.
-
Data Manageability: Divides tables and indexes into smaller and more manageable units.
Disadvantages:
-
Complexity: The first difficulty that people encounter with sharding is the sheer complexity of properly implementing a sharded database architecture. If done incorrectly, there’s a significant risk that the sharding process can lead to lost data or corrupted tables. Even when done correctly, though, sharding is likely to have a major impact on your team’s workflows. Rather than accessing and managing one’s data from a single entry point, users must manage data across multiple shard locations, which could potentially be disruptive to some teams.
-
Joins across shards: Once a database is partitioned and spread across multiple machines it is often not feasible to perform joins that span multiple database shards. Such joins will not be performance efficient since data has to be retrieved from multiple servers.
-
Rebalancing: One problem that users sometimes encounter after having sharded a database is that the shards eventually become unbalanced. By way of example, let’s say you have a database with two separate shards, one for customers whose last names begin with letters A through M and another for those whose names begin with the letters N through Z. However, your application serves an inordinate amount of people whose last names start with the letter G. Accordingly, the A-M shard gradually accrues more data than the N-Z one, causing the application to slow down and stall out for a significant portion of your users. The A-M shard has become what is known as a database hotspot. In this case, any benefits of sharding the database are canceled out by the slowdowns and crashes. The database would likely need to be repaired and resharded to allow for a more even data distribution.
When to use sharding? Here are some reasons where sharding might be the right choice:
- Leveraging existing hardware instead of high-end machines.
- Maintain data in distinct geographic regions.
- Quickly scale by adding more shards.
- Better performance as each machine is under less load.
- When more concurrent connections are required.
Consistent Hashing
In traditional hashing-based distribution methods, we use a hash function to hash our partition keys (i.e. request ID or IP). Then if we use the modulo against the total number of nodes (server or databases). This will give us the node where we want to route our request.
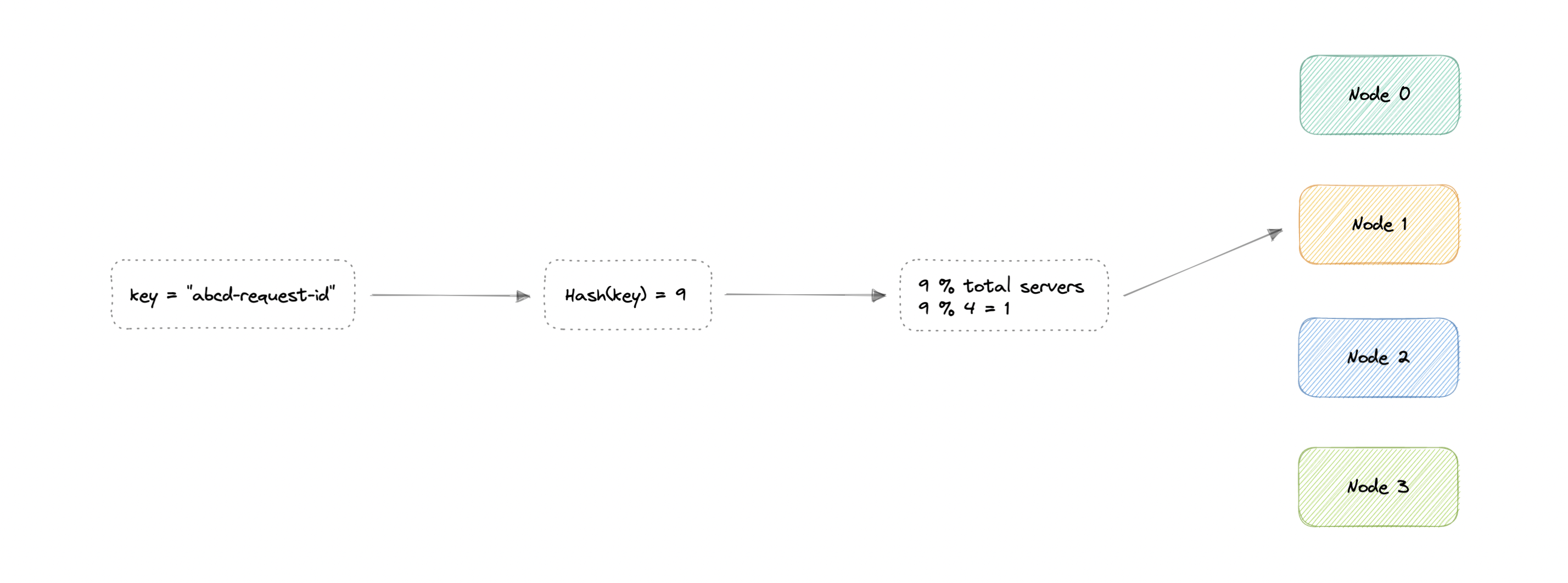
The problem with this is if we add or remove a node, it will cause N to change, meaning our mapping strategy will break as the same requests will now map to a different server. As a consequence, the majority of requests will need to be redistributed which is very inefficient.
We want to uniformly distribute requests among different nodes such that we should be able to add or remove nodes with minimal effort. Hence, we need a distribution scheme that does not depend directly on the number of nodes (or servers), so that, when adding or removing nodes, the number of keys that need to be relocated is minimized.
Consistent Hashing is a distributed hashing scheme that operates independently of the number of nodes in a distributed hash table by assigning them a position on an abstract circle, or hash ring. This allows servers and objects to scale without affecting the overall system.
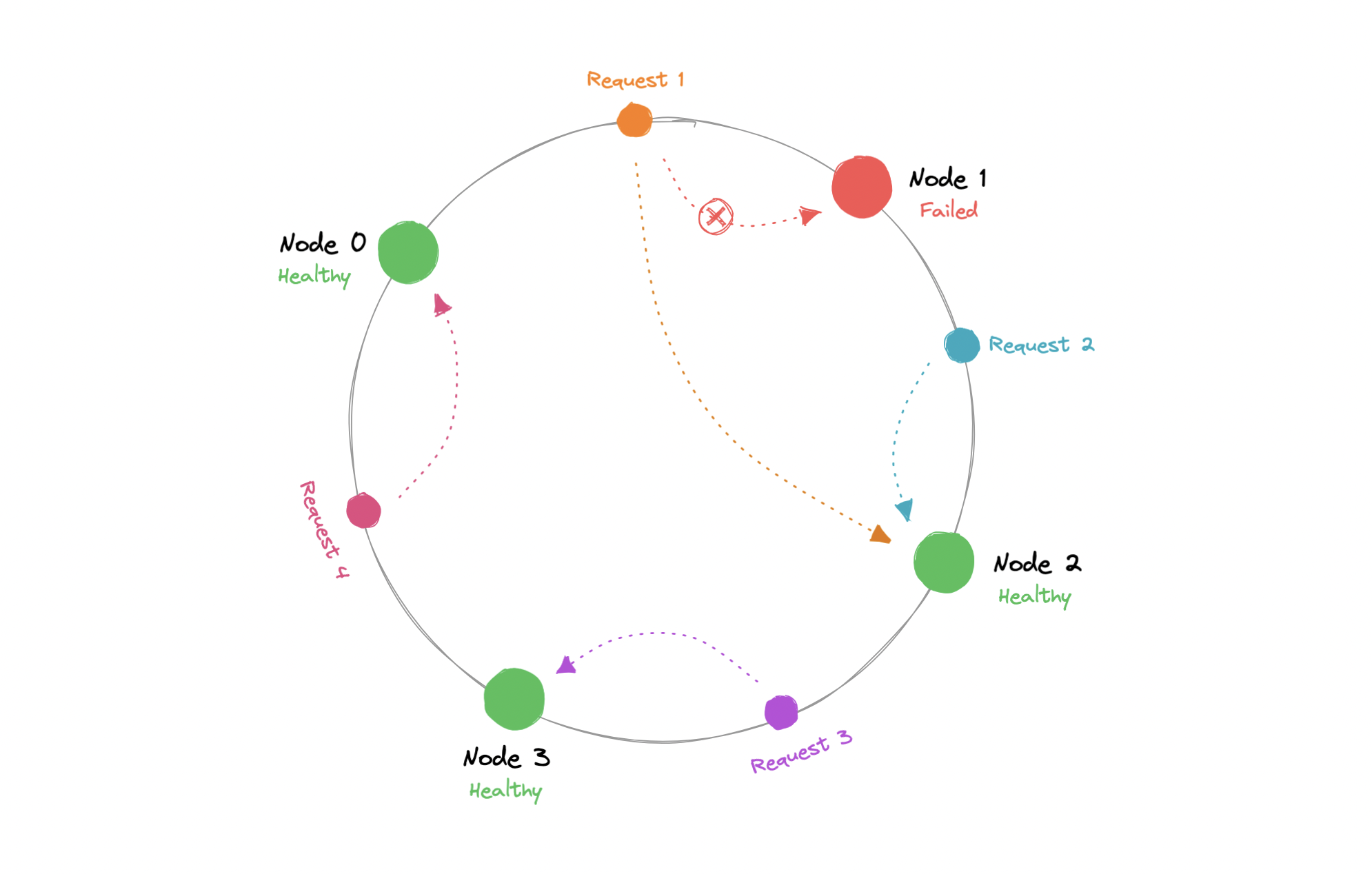
Using consistent hashing, only K/N data would require re-distributing.
Now, when the request comes in we can simply route it to the closest node in a clockwise (can be counterclockwise as well) manner. This means that if a new node is added or removed, we can use the nearest node and only a fraction of the requests need to be re-routed.
In theory, consistent hashing should distribute the load evenly however it doesn't happen in practice. Usually, the load distribution is uneven and one server may end up handling the majority of the request becoming a hotspot, essentially a bottleneck for the system. We can fix this by adding extra nodes but that can be expensive.
Let's see how we can address these issues.
Virtual Nodes
In order to ensure a more evenly distributed load, we can introduce the idea of a virtual node, sometimes also referred to as a VNode.
Instead of assigning a single position to a node, the hash range is divided into multiple smaller ranges, and each physical node is assigned several of these smaller ranges. Each of these subranges is considered a VNode. Hence, virtual nodes are basically existing physical nodes mapped multiple times across the hash ring to minimize changes to a node's assigned range.
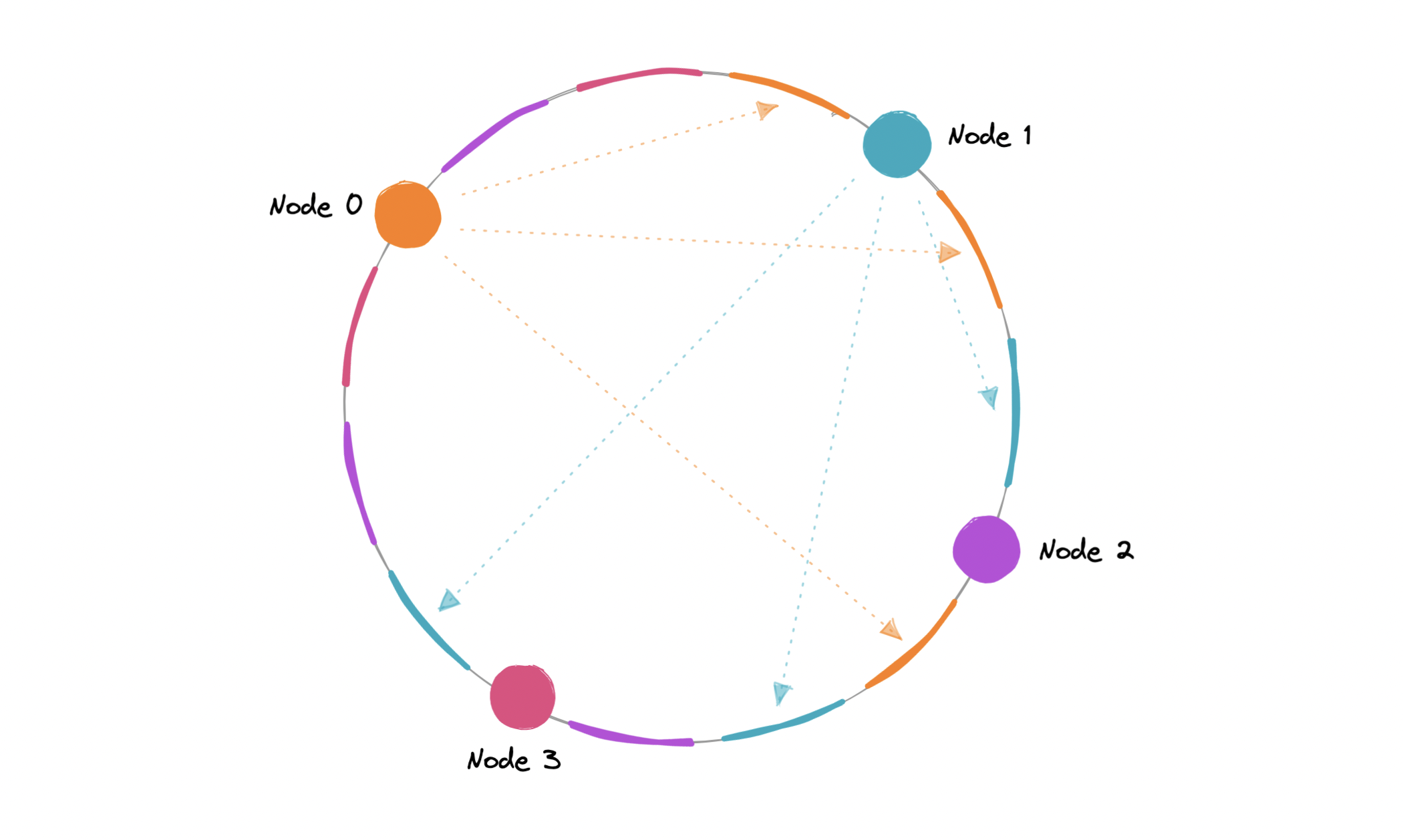
As VNodes help spread the load more evenly across the physical nodes on the cluster by diving the hash ranges into smaller subranges, this speeds up the re-balancing process after adding or removing nodes. This also helps us reduce the probability of hotspots.
Data replication
To ensure high availability and durability, consistent hashing replicates each data item on multiple N nodes in the system where the value N is equivalent to the replication factor.
The replication factor is the number of nodes that will receive the copy of the same data. In eventually consistent systems, this is done asynchronously.
Advantages:
-
Makes rapid scaling up and down more predictable.
-
Facilitates partitioning and replication across nodes.
-
Enables scalability and availability.
-
Reduces hotspots.
-
Disadvantages:
-
Increases complexity.
-
Cascading failures.
-
Load distribution can still be uneven.
-
Key management can be expensive when nodes transiently fail.
Database Concurrency Control
Concurrency Control in Database Management System is a procedure of managing simultaneous operations without conflicting with each other. It ensures that Database transactions are performed concurrently and accurately to produce correct results without violating data integrity of the respective Database.
Concurrent access is quite easy if all users are just reading data. There is no way they can interfere with one another. Though for any practical Database, it would have a mix of READ and WRITE operations and hence the concurrency is a challenge.
DBMS Concurrency Control is used to address such conflicts, which mostly occur with a multi-user system. Therefore, Concurrency Control is the most important element for proper functioning of a Database Management System where two or more database transactions are executed simultaneously, which require access to the same data.
The component of a Database Management System (DBMS) responsible for concurrency control is typically the concurrency control manager or module. This component ensures that multiple transactions can execute concurrently without interfering with each other in a way that would compromise the consistency and integrity of the database.
Different concurrency control protocols offer different benefits between the amount of concurrency they allow and the amount of overhead that they impose. Following are the Concurrency Control techniques in DBMS:
- Lock-Based Protocols
- Two Phase Locking Protocol
- Timestamp-Based Protocols
- Validation-Based Protocols
Lock-based Protocols
Lock Based Protocols in DBMS is a mechanism in which a transaction cannot Read or Write the data until it acquires an appropriate lock. Lock based protocols help to eliminate the concurrency problem in DBMS for simultaneous transactions by locking or isolating a particular transaction to a single user.
A lock is a data variable which is associated with a data item. This lock signifies that operations that can be performed on the data item. Locks in DBMS help synchronize access to the database items by concurrent transactions.
All lock requests are made to the concurrency-control manager. Transactions proceed only once the lock request is granted.
Binary Locks: A Binary lock on a data item can either locked or unlocked states.
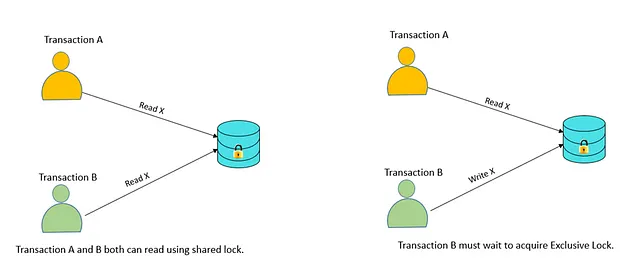
Shared/exclusive: This type of locking mechanism separates the locks in DBMS based on their uses. If a lock is acquired on a data item to perform a write operation, it is called an exclusive lock.
- Shared Lock (S):
A shared lock is also called a Read-only lock. With the shared lock, the data item can be shared between transactions. This is because you will never have permission to update data on the data item.
For example, consider a case where two transactions are reading the account balance of a person. The database will let them read by placing a shared lock. However, if another transaction wants to update that account’s balance, shared lock prevent it until the reading process is over.
- Exclusive Lock (X):
With the Exclusive Lock, a data item can be read as well as written. This is exclusive and can’t be held concurrently on the same data item. X-lock is requested using lock-x instruction. Transactions may unlock the data item after finishing the ‘write’ operation.
For example, when a transaction needs to update the account balance of a person. You can allows this transaction by placing X lock on it. Therefore, when the second transaction wants to read or write, exclusive lock prevent this operation.
- Simplistic Lock Protocol
This type of lock-based protocols allows transactions to obtain a lock on every object before beginning operation. Transactions may unlock the data item after finishing the ‘write’ operation.
- Pre-claiming Locking
Pre-claiming lock protocol helps to evaluate operations and create a list of required data items which are needed to initiate an execution process. In the situation when all locks are granted, the transaction executes. After that, all locks release when all of its operations are over.
Starvation
Starvation is the situation when a transaction needs to wait for an indefinite period to acquire a lock.
Following are the reasons for Starvation:
- When waiting scheme for locked items is not properly managed
- In the case of resource leak
- The same transaction is selected as a victim repeatedly
Two Phase Locking
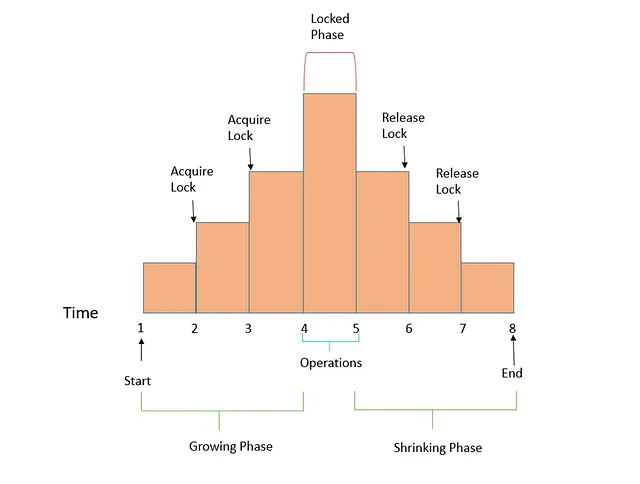
Two-Phase Locking (2PL) is a concurrency control mechanism that operates on the principle that transactions need to acquire locks on data items before reading or modifying them. It consists of two main phases: the Growing Phase, where transactions acquire locks, and the Shrinking Phase, where locks are released. Hence the name, 2PL.
Note that while two-phase locking (2PL) sounds very similar to two-phase commit (2PC), they are completely different things. 2PL manages locks in databases, while 2PC coordinates distributed transactions for data consistency.
In a distributed system with multiple concurrent users, Serializability means each transaction behaves as if it’s the sole active one in the entire database. For around 30 years, there was only one widely used algorithm for serializability in databases: two-phase locking (2PL). 2PL is one of the methods to achieve Serializability.
In 2PL several transactions are allowed to concurrently read the same object as long as nobody is writing to it. But as soon as anyone wants to write (modify or delete) an object, exclusive access is required:
-
If transaction A has read an object and transaction B wants to write to that object, B must wait until A commits or aborts before it can continue. (This ensures that B can’t change the object unexpectedly behind A’s back.)
-
If transaction A has written an object and transaction B wants to read that object, B must wait until A commits or aborts before it can continue. (Reading an old version of the object is not acceptable under 2PL.)
In 2PL, writers don’t just block other writers; they also block readers and readers block writers. That is, several transactions reading the same object use a shared lock while a transaction writing to the object must acquire an exclusive lock. If a transaction first reads and then writes an object, it may upgrade its shared lock to an exclusive lock. The upgrade works the same as getting an exclusive lock directly.
Growing Phase (Lock Acquisition):
- Transaction A begins and writes to an object, obtaining a write lock on it.
- Transaction B starts and intends to read the same object but finds it locked by A.
- Transaction B must wait during the growing phase since it cannot acquire a read lock on the object while A holds a write lock.
Shrinking Phase (Lock Release):
- Transaction A completes its writing operation and releases the write lock on the object.
- Now, Transaction B, which was waiting, acquires a read lock and proceeds with its reading operation.
- Transaction B ensures it reads the most up-to-date version of the object.
In both scenarios, Two-Phase Locking (2PL) ensures that transactions A and B do not interfere with each other’s access to the shared object. During the growing phase, one transaction acquires a lock, preventing the other from acquiring a conflicting lock. In the shrinking phase, the locks are released, allowing the waiting transaction to proceed, ensuring data consistency, and preventing unexpected changes or outdated reads.
Timestamp-based Protocols
Timestamp based Protocol in DBMS is an algorithm which uses the System Time or Logical Counter as a timestamp to serialize the execution of concurrent transactions. The Timestamp-based protocol ensures that every conflicting read and write operations are executed in a timestamp order.
The older transaction is always given priority in this method. It uses system time to determine the time stamp of the transaction. This is the most commonly used concurrency protocol.
Lock-based protocols help you to manage the order between the conflicting transactions when they will execute. Timestamp-based protocols manage conflicts as soon as an operation is created.
Advantages:
- Schedules are serializable just like 2PL protocols
- No waiting for the transaction, which eliminates the possibility of deadlocks!
Disadvantages:
- Starvation is possible if the same transaction is restarted and continually aborted
Validation Based Protocol
Validation based Protocol in DBMS also known as Optimistic Concurrency Control Technique is a method to avoid concurrency in transactions. In this protocol, the local copies of the transaction data are updated rather than the data itself, which results in less interference while execution of the transaction.
The Validation based Protocol is performed in the following three phases:
- Read Phase
- Validation Phase
- Write Phase
Read Phase
- In the Read Phase, the data values from the database can be read by a transaction but the write operation or updates are only applied to the local data copies, not the actual database.
Validation Phase
- In Validation Phase, the data is checked to ensure that there is no violation of serializability while applying the transaction updates to the database.
Write Phase
- In the Write Phase, the updates are applied to the database if the validation is successful, else; the updates are not applied, and the transaction is rolled back.
Database Recovery Management
Database recovery restores a database from a given state (usually inconsistent) to a previously consistent state. Recovery techniques are based on the atomic transaction property: all portions of the transaction must be treated as a single, logical unit of work in which all operations are applied and completed to produce a consistent database. If a transaction operation cannot be completed for some reason, the transaction must be aborted and any changes to the database must be rolled back (undone). In short, transaction recovery reverses all of the changes that the transaction made to the database before the transaction was aborted.
Write-Ahead Log Protocol (WAL)
The Write-Ahead Log (WAL) protocol is a method used in database management systems to ensure durability and recoverability of transactions. In WAL, before any modifications are made to the database, a corresponding log entry is written to a persistent log file on disk. This log entry contains the details of the modification operation.
The key principle of WAL is that the log entry must be written to disk before the corresponding database modification is made. This ensures that in the event of a system failure or crash, the log can be used to reconstruct the state of the database and recover any transactions that were in progress at the time of the failure.
Redundant Transaction Logs
Redundant transaction logs refer to having multiple copies of transaction logs stored in different locations or on different storage media. This redundancy is implemented to enhance the reliability and fault tolerance of the database recovery process.
By maintaining redundant copies of transaction logs, the risk of data loss due to hardware failures, disk corruption, or other system issues is mitigated. If one copy of the transaction log becomes inaccessible or corrupted, the database recovery process can still proceed using the redundant copies.
Database Buffers
Database buffers, also known as buffer pools, are areas of memory used by database management systems to cache frequently accessed data pages from the disk. When a query or transaction requests data from the database, the database system first checks if the required data is already in the buffer pool. If it is, the data is retrieved from memory, which is much faster than reading it from disk.
The use of database buffers helps improve the overall performance of the database system by reducing the frequency of disk reads. It also helps to reduce contention for disk resources and can improve concurrency by reducing the time spent waiting for disk I/O operations to complete.
Database Checkpoints
A database checkpoint is a point-in-time snapshot of the database that represents a consistent state of the data. During normal operation, the database management system periodically performs checkpoints to write all in-memory modified data pages to disk.
Checkpoints serve several purposes in database management:
-
Recovery: Checkpoints provide a known point from which the recovery process can start in the event of a system failure or crash. By ensuring that all modified data pages are written to disk, checkpoints help minimize the amount of work required to restore the database to a consistent state.
-
Performance: Checkpoints help reduce the time required for database recovery by limiting the number of transactions that need to be rolled back or rolled forward during the recovery process. By periodically flushing modified data pages to disk, checkpoints help prevent the transaction log from growing excessively large, which can degrade database performance.
-
Space Management: Checkpoints also help manage disk space usage by allowing the database management system to recycle log files and reclaim disk space that is no longer needed. After a checkpoint is performed, the log entries for transactions that were committed before the checkpoint can be safely discarded, as they are no longer needed for recovery purposes.